
About
I am a researcher at NTT Communication Science Laboratories, a research institute of the Japanese telecommunications company NTT. I received my Ph.D. in Informatics from Kyoto University under the supervision of Hisashi Kashima. Before joining NTT, I specialized in systems biology and bioinformatics at Keio University and the University of Tokyo, working under the supervision of Akira Funahashi and Satoru Miyano.
News
2026.04
My grant proposal, Causal Inference from Incomplete Data for Fair Machine Learning Predictions, has been accepted for the acceleration phase of JST ACT-X, with total funding of over JPY 10 million. In this phase, I will work on tackling key challenges in causality-based fairness.
2026.04
I am honored to be invited to the Japan Prize award ceremony, where Professor Cynthia Dwork, a pioneer of individual fairness and differential privacy, will receive this prestigious prize. As a researcher working on fairness, I look forward to the roundtable discussions with her.
2025.09
I am serving as an organizing committee at IBIS2025. I will organize Student Networking Program to facilitate interactions among students and young researchers in the machine learning community. See you in Okinawa!
2024.09
I am serving as a part-time lecturer at Doshisha University. This autumn semester, I will deliver 15 classes on the basics of mathematical statistics, namely, point and interval estimation, hypothesis testing, and analysis of variance (ANOVA). (Course curriculum page (in Japanese)).
2024.04
Our paper, entitled Differentiable Pareto-Smoothed Weighting for High-Dimensional Heterogeneous Treatment Effect Estimation, has been accepted to UAI 2024 (acceptance rate: 27.0%). In this work, we propose differentiable Pareto smoothing, an end-to-end inverse probability weighting (IPW) correction framework for improving the stability of conditional average treatment effect (CATE) estimation.
2023.12
Our joint work, entitled Uncertainty Quantification in Heterogeneous Treatment Effect Estimation with a Gaussian-Process-Based Partially Linear Model, has been accepted to AAAI 2024. We present a Bayesian semi-parametric model for uncertainty quantification in conditional average treatment effect (CATE) estimation.
Biography
I work at the intersection of causal inference and machine learning. My current research focuses on developing fundamental methods for causal inference from incomplete data—that is, real-world data that present various challenges, including small sample sizes, high dimensionality, and complex measurement noise. I believe such causal inference techniques provide an essential foundation for making scientific discoveries and enabling reliable machine learning.
Education
Ph.D. of Informatics
2019.10 - 2022.09
Kashima Lab., Dept. of Intelligence Science & Technology, Graduate School of Informatics, Kyoto University, Japan.
Ph.D. Dissertation: Causal Inference for Scientific Discoveries and Fairness-Aware Machine Learning
Key Words: Causal discovery, Treatment effect estimation, Machine learning and fairness
Master of Information Science & Technology
2013.04 - 2015.03
Miyano Lab., Dept. of Computer Science, Graduate School of Information Science and Technology, The University of Tokyo, Japan.
Master Thesis: An Infinite Relational Model for Integrative Analysis of Cancer Genome Data
Key Words: Bioinformatics, Omics data analysis, Non-parametric Bayesian models, Survival time analysis
Bachelor of Science
2009.04 - 2013.03
Funahashi Lab., Dept. of Biosciences and Informatics, Faculty of Science and Technology, Keio University, Japan.
Bachelor Thesis: Developing Biochemical Network Simulator with Adaptive Step Size Numerical Integration
Key Words: Systems biology, Ordinary differential equations, Numerical integration, Bifurcation analysis
Professional Experience
Principal investigator
2023.10 - 2027.03
ACT-X, Japan Science and Technology Agency (JST)
- Grant proposal: Causal Inference from Incomplete Data for Fair Machine Learning Predictions
- 2023.10 - 2026.03: 5,000,000 JPY (Acceptance rate: 19.9%)
- 2026.04 - 2027.03: 5,000,000 JPY (Full grant in the acceleration phase)
Research scientist
2015.04 - Present
Learning and Intelligent Systems Group, Innovative Communication Laboratory, Communication Science Laboratories, Kyoto, Japan.
- Causal discovery
- Granger causality inference via supervised learning (IJCAI2018, TOM2018)
- Treatment effect estimation
- Selection of distributional treatment effect modifiers for causal mechanism understanding (UAI2022)
- Uncertainty quantification of conditional average treatment effect (CATE) via Gaussian-process-based partially linear model (AAAI2024)
- Weighted representation learning with differentiable Pareto-smoothed weights for CATE estimation from high-dimensional observational data (UAI2024)
- CATE estimation under few-shot setting via meta-learning of meta-learner models (Machine Learning 2024)
- Machine learning and causality-based fairness
- Achieving path-specific counterfactual fairness under milder assumptions (AISTATS2021, DAMI2022)
Teaching
Adjunct lecturer
2026 (Spring)
The University of Osaka
- Special Lectures on Information Science & Technology I
- Introduction to Statistical Causal Inference: Bayesian networks, Structural causal models (SCMs), and Potential outcome framework
- [URL (in Japanese)]
Adjunct lecturer
2025 (Spring)
The University of Osaka
- Special Lectures on Information Science & Technology I
- Introduction to Statistical Causal Inference: Bayesian networks, Structural causal models (SCMs), and Potential outcome framework
- [URL (in Japanese)]
Adjunct lecturer
2024 (Fall)
Doshisha University
- Applied Statistics
- Point and interval estimation, Hypothesis testing, and Analysis of variance (ANOVA)
- [URL (in Japanese)]
Adjunct lecturer
2024 (Spring)
The University of Osaka
- Special Lectures on Information Science & Technology I
- Introduction to Statistical Causal Inference: Bayesian networks, Structural causal models (SCMs), and Potential outcome framework
- [URL (in Japanese)]
Awards, Invited Talks, and Social Activities
Invited Talk
2026.08
EcoSta2026
- Toward Interventionally Fair Decision-Making under Partial Causal Graph Knowledge
- Organized Session "Recent advances in causal inference: from structure learning to effect estimation"
- The 9th International Conference on Econometrics and Statistics (EcoSta2026) [URL ]
Media Publication
2026.05
NTT CS Labs. Open House 2026
- Who is affected by this policy, and why?
- Accurate and interpretable statistical causal effect estimation
- NTT CS Labs. Open House 2026 [URL ]
Social Activity
2026.04
Japan Prize award ceremony
- Roundtable discussions with the Japan Prize award winner, Prof. Cynthia Dwork
- Japan Prize award ceremony 2026 [URL ]
Academic Activity
2025.11
IBIS2025 Program Committee
- Organization of networking program for students
- The 28-th Information-based Induction Sciences (IBIS2025) [URL]
Award
2023.05
UAI2023
- Top Reviewer Award
- The 39th International Conference on Uncertainty in Artificial Intelligence (UAI2023) [URL ]
Selected Research Topics
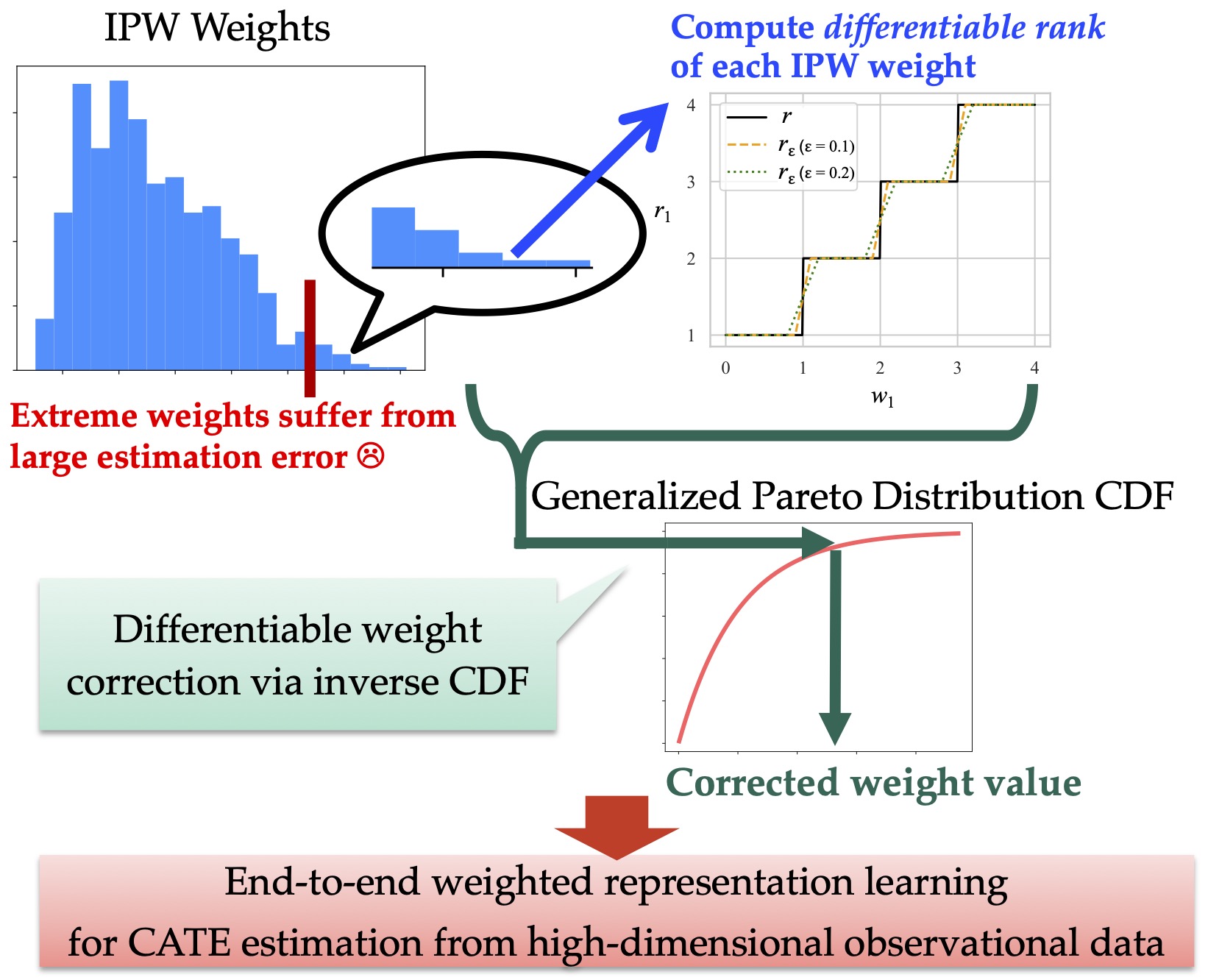
Differentiable Pareto-Smoothed Weighting for High-Dimensional Heterogeneous Treatment Effect Estimation
Assessing the effects of a treatment (e.g., drug administration) provides deep insights into treatment effect heterogeneity across individuals and supports effective decision-making in various fields, such as precision medicine, personalized education, and targeted advertising.
To estimate heterogeneous treatment effects from observational data, it is necessary to distinguish true causal effects from spurious correlations induced by confounders—features of individuals that influence both their treatment choices and outcomes. Since it is often unclear which features act as confounders, practitioners tend to include as many features as possible in their datasets. This, however, leads to the challenge of high-dimensional heterogeneous treatment effect estimation.
A promising approach for such high-dimensional settings is weighted representation learning, which decomposes observed features into representations of confounders and other features by minimizing a weighted prediction loss. This data-driven decomposition helps preserve predictive information from adjustment variables—features that are not confounders but are predictive of potential outcomes. In practice, however, the performance of this approach can degrade due to the numerical instability of the weight values, which are computed as the inverse of conditional probabilities using a technique known as inverse probability weighting (IPW).
To address this issue, we propose an effective, end-to-end weight correction framework that combines Pareto smoothing from extreme value statistics with differentiable ranking from machine learning. The resulting differentiable Pareto-smoothed weighting framework enables stable learning of feature representations from high-dimensional data and achieves improved performance in treatment effect estimation.
-
Yoichi Chikahara, Kansei Ushiyama. Differentiable Pareto-Smoothed Weighting for High-Dimensional Heterogeneous Treatment Effect Estimation. Proc. of the 40th International Conference on Uncertainty in Artificial Intelligence. Barcelona, Spain, July 2024 (UAI2024; Acceptance Rate: 27%) [Preprint] [Openreview] [Proceedings] [Paper(PDF)] [Poster(PDF)] [Code]
-
"Who is affected by this policy, and why?",
Exhibition 06, NTT Communication Science Laboratories OPEN HOUSE 2026,
[Link (to appear)]
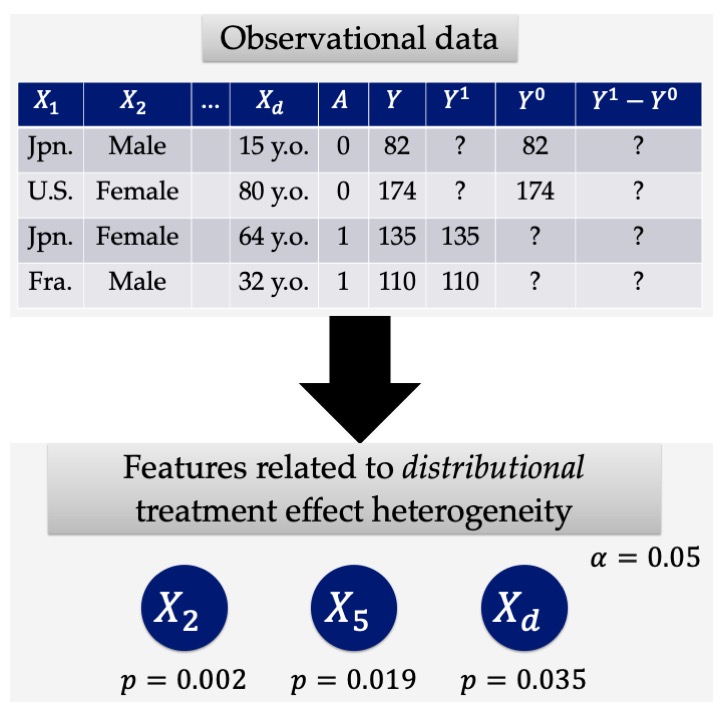
Feature Selection for Discovering Distributional Treatment Effect Modifiers
The statistical estimation of treatment (or intervention) effects is critically important in a wide range of applications, such as precision medicine, personalized education, and targeted advertising. For example, predicting the effects of a medical treatment (e.g., drug administration or vaccination) on health outcomes is essential for advancing precision medicine, while inferring the impacts of education and training programs can support personalized education.
The magnitude of such treatment effects often varies across individuals, and understanding why this treatment effect heterogeneity arises is a problem of great importance. A popular traditional approach to explaining treatment effect heterogeneity is to identify individual attributes that are relevant to the magnitude of the treatment effect. The challenge is that a treatment effect for each individual cannot be directly measured, as it is defined as the difference between potential outcomes—i.e., the outcomes when an individual is treated and when they are not—which can never be jointly observed. Consequently, existing methods often rely on the average treatment effect across individuals with the same attribute, which can be estimated from observational data. However, such mean-based methods may overlook important attributes that do not influence the average treatment effect but do affect other aspects of the distribution, such as the variance of the treatment effect.
To address this limitation, we propose a feature selection framework for discovering distributional treatment effect modifiers. Our approach introduces a feature importance measure based on the kernel maximum mean discrepancy (MMD) and derives a multiple-testing-based algorithm that can control the type I error rate (i.e., the proportion of false positives) at a desired level.
-
Yoichi Chikahara, Makoto Yamada, Hisashi Kashima. Feature Selection for Discovering Distributional Treatment Effect Modifiers. Proc. of the 38th International Conference on Uncertainty in Artificial Intelligence. Eindhoven, Netherlands, August 2022 (UAI2022) [Preprint] [Openreview] [Proceedings] [Paper(PDF)] [Spotlight Slides(PDF)] [Poster(PDF)]
-
"Who is affected by this policy, and why?",
Exhibition 06, NTT Communication Science Laboratories OPEN HOUSE 2026,
[Link (to appear)]
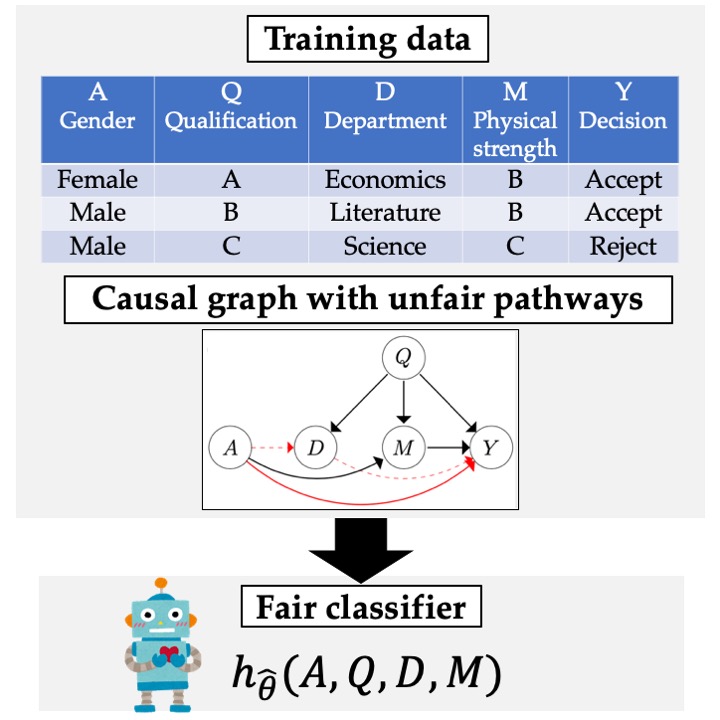
Learning Individually Fair Classifier with Path-Specific Causal-Effect Constraint
Machine learning is increasingly being used to make decisions that have a profound impact on people’s lives (e.g., hiring, lending, and recidivism prediction). For such applications, it is critically important to learn a fair predictive model—one that makes decisions that are fair with respect to sensitive attributes (e.g., gender, race, religion, disabilities, and sexual orientation). Determining whether a decision is discriminatory can be difficult, as perceptions of discrimination often depend on the real-world context. For example, in hiring decisions for physically demanding jobs, it may not be considered discriminatory to reject applicants based on physical strength.
Such prior knowledge about what decisions should be regarded as discriminatory can be represented as a causal graph with unfair pathways. Several methods have been proposed to learn fair predictive models by imposing constraints on the causal effects along these unfair pathways; however, none of them can guarantee fairness at the individual level without making impractical assumptions about the data.
To address this issue, we formulate an optimization problem in which unfair causal effects are constrained to be zero for each individual. We introduce the Probability of Individual Unfairness (PIU), defined as the probability that the causal effect for an individual is nonzero, and solve an optimization problem that constrains the PIU to zero. Although PIU cannot be directly estimated from data, we derive an upper bound on PIU using the concept of the correlation gap and propose solving an optimization problem that constrains this upper bound to zero.
-
Yoichi Chikahara, Shinsaku Sakaue, Akinori Fujino, Hisashi Kashima. Learning Individually Fair Classifier with Path-Specific Causal-Effect Constraint. Proc. of the 24th International Conference on Artificial Intelligence and Statistics. Online, April 2021 (AISTATS2021) [Preprint][Proceedings] [Paper (PDF)] [3-min. Video (Link)] [Slides (PDF)] [Poster (PDF)]
-
Yoichi Chikahara, Shinsaku Sakaue, Akinori Fujino, Hisashi Kashima. Making Individually Fair Predictions with Causal Pathways. Special Issue on "Bias and Fairness in AI", Data Mining and Knowledge Discovery (DAMI), 2022 [Article] [View-only shared link]
-
"Accurate and Fair Machine Learning based on Causality", The 6th StatsML Symposium (StatsML2022), Online, February 2022. [Abst] [Slides]
-
Ask me how to make a fair decision for everyone [Link], NTT Communication Science Laboratories OPEN HOUSE 2021
-
Fair predictions using causal inference - NTT and Kyoto University has developed a novel machine learning technology -, Nikkan Kogyo Shimbun, 2021/06/02 (page 5). [Link]
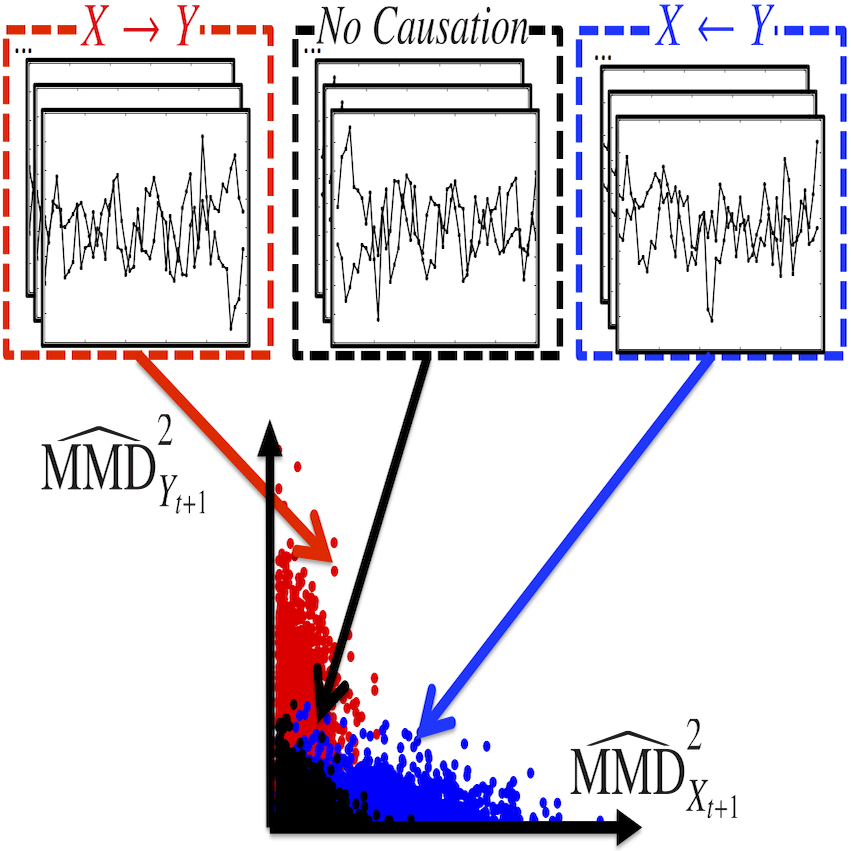
Causal Inference in Time Series via Supervised Learning
Discovering causal relationships in time series is one of the most important tasks in time series analysis, with key applications in various domains. For example, identifying a causal relationship in which research and development (R&D) expenditure X influences total sales Y, but not vice versa (i.e., X → Y), can support decision-making in companies. In bioinformatics, uncovering causal (regulatory) relationships between genes from time series gene expression data is also a central problem.
For such applications, the notion of temporal causality known as Granger causality [Granger, 1969] has been widely used. The concept is straightforward: if the past values of X are “helpful” in predicting the future values of Y, then X is considered a cause of Y. To quantify this “helpfulness,” many traditional methods employ regression models, which are mathematical expressions representing the relationships between variables. When an appropriate regression model is well fitted to the data, these methods can identify the correct causal directions. However, selecting an appropriate regression model for each dataset is challenging, as it requires a deep understanding of the data—for example, the sample size, the nature of the relationships between variables, and the noise structure.
Our goal is to develop a novel approach that does not require such detailed prior knowledge of the data. To this end, we propose a supervised learning framework that uses a classifier instead of regression models. Specifically, we infer causal relationships by training a classifier to assign ternary causal labels (X → Y, X ← Y, or No Causation) to time series data.
-
Yoichi Chikahara, Akinori Fujino. Causal Inference in Time Series via Supervised Learning. Proc. of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, July 2018 (IJCAI2018; Acceptance Rate: 20%)[Proceedings] [Paper] [Slides] [Poster]
-
"Causal Inference in Time Series via Supervised Learning", Top Conference Session (Machine Learning) Forum on Information Technology (FIT2019), Okayama University, Okayama, September 2019 [PDF]
-
"Which is cause? Which is effect? Learn from data!",
Exhibition 05, NTT Communication Science Laboratories OPEN HOUSE 2019,
[Link]
Publications
See here for my publication list.
Skills
I have pursued research across a broad range of topics in statistical causal inference, without limiting my focus to a single subfield. My work encompasses causal graph estimation, causal effect estimation, and causality-based fairness. To address challenges in these areas, I draw on tools from related fields in machine learning, statistics, and mathematical optimization, including kernel methods, stochastic programming, feature selection, deep representation learning, Pareto smoothing, and meta-learning.
I am also interested in foreign languages. In 2024, I passed the pre-1st grade of the Diplôme d'Aptitude Pratique au Français (Test in Practical French Proficiency), which had an acceptance rate of 20.0%.



Contact
Please feel free to contact us with any questions or inquiries. We welcome proposals for research collaborations, invitations to give talks, and other inquiries related to our research activities.

Location:
2-4 Hikaridai, Seika-cho, Soraku-gun, Kyoto, 619-0237, Japan
Email:
chikahara.yoichi (ζ) gmail.com